Kódování Unicode: standardní kódování znaků
Každý uživatel internetu v pokusechnastavit jednu nebo jinou funkci alespoň jednou viděnou na displeji napsanou latinským písmem slovo "Unicode". Co je to, dozvíte se v tomto článku.

Definice
Kódování Unicode je kódovací standardznaků. Byla navržena neziskovou organizací Unicode Inc. v roce 1991. Standard je navržen tak, aby v jednom dokumentu kombinoval co nejvíce různých typů symbolů. Stránka, která je na jejím základě vytvořena, může obsahovat písmena a hieroglyfy z různých jazyků (z ruštiny do korejštiny) a matematické znaky. Všechny znaky v tomto kódování jsou zobrazeny bez problémů.
Důvody pro vytvoření
Kdysi dávno, dlouho před vznikem jednotného systému"Unicode", kódování bylo vybráno na základě preferencí autora dokumentu. Z tohoto důvodu často četl jeden dokument, museli jste použít různé tabulky. Někdy to muselo být provedeno několikrát, což značně komplikovalo život běžného uživatele. Jak již bylo řečeno, řešení tohoto problému v roce 1991 navrhla nezisková organizace Unicode Inc., která navrhla nový typ kódování znaků. Byl povolán, aby spojil morálně zastaralé a rozmanité standardy. "Unicode" - kódování, které umožnilo dosáhnout v té době nemyslitelné: vytvořit nástroj, který podporuje obrovské množství znaků. Výsledek překonal mnoho očekávání - objevily se dokumenty, které obsahovaly současně anglický a ruský text, latinské a matematické výrazy.
Ale předcházelo vytvoření jediného kódovánípotřeba vyřešit řadu problémů, které vznikly v důsledku velkého množství standardů, které v té době existovaly. Mezi nejčastější patří:
- elfické spisy nebo "karkozyabry";
- omezená sada znaků;
- problém kódování konverze;
- duplikace písem.

Krátké historické odbočení
Představte si, že dvůr je 80 let. Počítačová technologie není tak rozšířená a má jinou formu než dnes. V tomto okamžiku je každý OS jedinečný svým vlastním způsobem a je každým nadšeným dokončen pro specifické potřeby. Potřeba výměny informací se změní v další revizi všeho na světě. Snaží číst dokument vytvořený pomocí jiného operačního systému, často se zobrazí zvláštní sadu znaků, a hra začíná kódování. To není vždy to udělat rychle a někdy nutné dokument nelze otevřít za šest měsíců, a ještě později. Lidé, kteří si často vyměňují informace, vytvářejí pro sebe konverzační tabulky. A pak pracovat na nich odhaluje zajímavý detail: nutnost vytvořit v obou směrech, „Z mého ve své“ tam a zpět. Dělat banální inverze výpočetní stroj nemůže za něj v pravém sloupci zdroje a levá - výsledek, ale ne obráceně. Pokud vidíte, že je třeba používat žádné speciální znaky v dokumentu, musely být přidány jako první, a pak další, a vysvětlit partnerovi, co potřebuje k tomu, aby tyto znaky nestanou „blábol“. A nezapomínejme, že pro každé kódování musel vyvinout nebo realizovat vlastní fonty, které vedly k vytvoření obrovského množství duplikátů v OS.
Představte si také, že na stránce písem vásZobrazí se 10 kusů identických Times New Roman s malými notacemi: pro utf-8, UTF-16, ANSI, UCS-2. Nyní pochopíte, že rozvoj univerzálního standardu byl naléhavou nutností?

"Otcové-tvůrci"
Počátky vytvoření Unicode by měly být hledány v roce 1987rok, kdy Joe Becker z společnosti Xerox společně s Lee Collinsem a Markem Davisem z Apple začal zkoumat praktickou tvorbu univerzálního znakového souboru. V srpnu 1988 vydal Joe Becker návrh na vytvoření 16bitového mezinárodního vícejazyčného kódovacího systému.
O pár měsíců později se jedná o pracovní skupinu Unicodebyl rozšířen o Ken Whistler a Mike Kernegan z RLG, Glenn Wright ze společnosti Sun Microsystems a několik dalších specialistů, kteří umožnili dokončení práce na předběžné přípravě jediného kódovacího standardu.

Obecný popis
Unicode je založen na pojetí symbolu. Tato definice je chápána jako abstraktní jev existující v konkrétní formě psaní a realizovaný grafemy (jeho "portréty"). Každý znak je nastaven v Unicode jedinečným kódem patřícím k určitému bloku standardu. Například grapheme B je v angličtině a ruské abecedě, ale v Unicode odpovídá 2 různým znakům. Převedou se na malé písmeno, to znamená, že každý z nich je popsán databázovým klíčem, sadou vlastností a úplným názvem.
Výhody Unicode
Od jiných současníků kódujících "Unicode"lišilo obrovskou rezervu znaků pro "šifrování" symbolů. Faktem je, že jeho předchůdci měli 8 bitů, tj. Podporovali 28 znaků, ale nový vývoj měl již 216 znaků, což byl obrovský krok kupředu. To umožnilo kódovat téměř všechny existující a distribuované abecedy.
S příchodem "Unicode" již není potřebapoužijte konverzní tabulky: jako jediný standard jednoduše zruší jejich potřebu. Stejně tak "krakozyabry" zmizely také do zapomnění - jediná norma to znemožnila, stejně jako vyloučila potřebu vytvářet duplicitní písma.
Vývoj Unicode
Samozřejmě, pokrok nezůstává stále a od okamžikuPrvní prezentace již prošla 25 let. Nicméně, charset „unicode“ tvrdošíjně udržuje svou pozici ve světě. V mnoha ohledech to bylo možné díky tomu, že se stal snadno implementovat a se rozšířila, byl uznán vývojáři proprietárního (placené) a open source software.
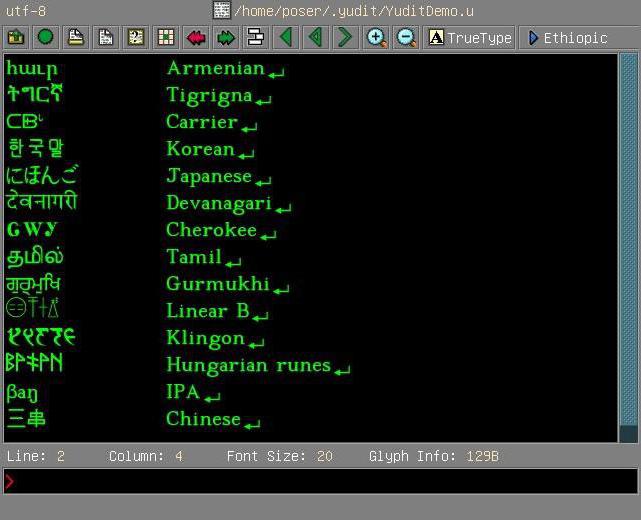
V tomto případě není nutné věřit, že dnes jsmestejné kódování Unicode je k dispozici již před čtvrtstoletím. V současné době se jeho verze změnila na hodnotu 5.x.x a počet kódovaných znaků se zvýšil na 231. Z možnosti použít větší počet znaků, které odmítly zachovat podporu pro kód Unicode-16 (kódování, kde bylo maximální číslo omezeno na 216). Od chvíle, kdy se objevil na verzi 2.0.0, "Unicode-standard" zvýšil počet znaků, které jej obsahovaly, téměř 2krát. Růst příležitostí pokračoval v následujících letech. K verzi 4.0.0 bylo již potřeba zvýšit standard samotný, což bylo provedeno. V důsledku toho společnost Unicode získala formu, v níž ji dnes známe.

Co jiného je v aplikaci Unicode?
Kromě obrovského, neustále doplňujícíhopočet znaků, kódování textových informací "Unicode" má ještě jednu užitečnou funkci. Mluvíme o tzv. Normalizaci. Namísto posouvání celého symbolu dokumentu podle znaku a nahrazení odpovídajících ikon z tabulky shody se použije jeden ze stávajících normalizačních algoritmů. O čem to mluvíme?
Namísto plýtvání výpočetními prostředkystroje pravidelně kontrolovat stejný symbol, který může být podobný v různých abecedách, používá speciální algoritmus. Umožňuje vygenerovat podobné znaky v samostatném grafu vyhledávací tabulky a odkazovat se na ně již a ne opakovat kontrolu všech dat.
Existují čtyři takové algoritmy vyvinuté a implementované. V každé z nich se transformace uskutečňuje podle striktně definovaného principu, který se liší od ostatních, a proto není možné označit jeden z nich za nejefektivnější. Každý byl vyvinut pro specifické potřeby, byl implementován a úspěšně použit.

Rozšiřování standardu
Po dobu 25 let své historie kódování "Unicode"pravděpodobně dostalo největší distribuci na světě. Podle tohoto standardu jsou také upraveny programy a webové stránky. Rozsah aplikace lze říci skutečností, že dnes Unicode využívá více než 60% internetových zdrojů.
Nyní víte, kdy se objevila standardní "Unicode". Co je to, také znáte a budete schopni ocenit celou hodnotu vynálezu vytvořenou skupinou specialistů společnosti Unicode Inc. před více než 25 lety.
</ p>




